
Spectral Networks and Deep Locally Connected Networks on Graphs
Motivation
Generalize ConvNet to graphs.
Spatial Construction
Consider an undirected weighted graph denoted by G=(V,W) where V={1,⋯,∣V∣} and W∈R∣V∣×∣V∣ is a symmetric nonnegative matrix.
Locality via W
The weights in a graph determine a notion of locality like the one in images, audio and text. We can restrict attention to sparse "filters" with receptive fields given by neighborhoods, thus reducing the number of parameters in a filter to O(S⋅n) where S is the average neighborhood size and n is the input feature size.
Multiresolution Analysis in Graphs
The authors mentioned that "[f]inding multiscale clusterings that are provably guaranteed to behave well w.r.t. Laplacian on the graph is still an open area of research" (the publication was in 2014).
Deep Locally Connected Networks
The spatial construction starts with a multiscale clustering of the graph. We consider K scales. We set V0=V, and for each k=1,⋯,K, we define Vk a partition of Vk−1 into dk clusters; and a collection of neighborhoods around each element of Vk−1:
With these in hand, we can now define the k-th layer of the network as a mapping: Rdk−1×fk−1→Rdk×fk, xk↦xk+1 defined as
where:
xk+1,j is the j th column of xk+1 and xk,i is the i th column of xk
Fk,i,j is a dk−1×dk−1 sparse matrix with nonzero entries in the locations given by Nk
Lk outputs the result of a pooling operation over each cluster in Vk.
This construction is illustrated below:
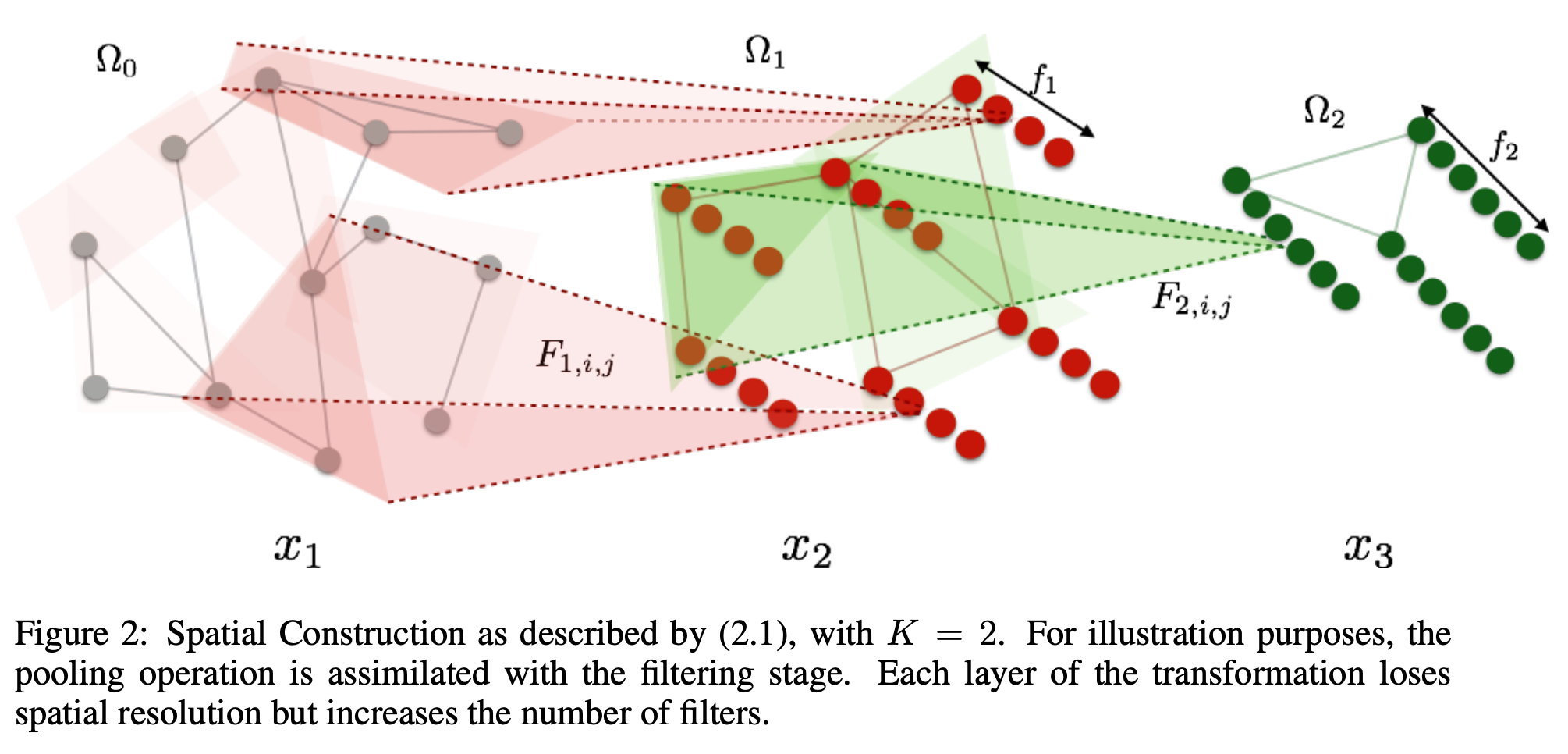
Started with W0=W, for all k≤K, Vk is constructed by merging all nodes whose pairwise distance (determined by the corresponding entry in Wk−1) are less than ε. Wk and Nk are then obtained with
where Vk(i) is the i th node in Vk, supp(Wk) is the support of Wk, i.e. {(i,j):Wk(i,j)>0}.
Spectral Construction
The global structure of the graph can be exploited with the spectrum of its graph-Laplacian to generalize the convolution operator.
Harmonic Analysis on Weighted Graphs
The frequency and smoothness relative to W are interrelated through the combinatorial Laplacian L=D−W or graph Laplacian L=I−D−21WD−21. For simplicity, the authors simply use the combinatorial Laplacian.
If x is an m-dimensional vector, a natural definition of the smoothness functional ∣∣∇x∣∣W2 at a node i is
This definition is also known as the Dirichlet energy. With this definition, the smoothest vector is a constant:
Note here ϕ0 is also the eigenvector of L corresponding to eigenvalue 0.
Each successive
is an eigenvalue of L, and the eigenvalues λi allow the smoothness of a vector x to be read off from the coefficients of x in [ϕ0,⋯,ϕm−1], equivalently as the Fourier coefficients of a signal defined in a grid. The filters are therefore multipliers on the eigenvalues of Δ and reduces the number of parameters of a filter from m2 to m.
Two related results are: 1. Functions that are smooth relative to the grid metric have coefficients with quick decay in the basis of eigenvectors of Δ. 2. The eigenvectors of the subsampled Laplacian are the low frequency eigenvectors of Δ.
Extending Convolutions via the Laplacian Spectrum
Theoretical Formulation
Given two functions f,g:Ω→R, Ω a Euclidean domain, the convolution of f and g is defined to be
where ∫Ω∣f(s)g(t−s)∣ds<∞.
A famous result related to convolution is the convolution theorem: f⋆g=f^⋅g^, where ^ denotes the fourier transform of a function and ⋅ denotes the elementwise multiplication.
The fourier transform of f∈L1(R) is defined by
The description above is for the Euclidean case. To generalize the notion of convolution to non-Euclidean case, one possibility is by using the convolution theorem as a definition.
Since Δ admits on a compact domain an eigendecomposition with a discrete set of orthonormal eigenfunctions ϕ0,ϕ1,⋯ and they are the smoothest functions in the sense of the Dirichlet energy, they can be interpreted as a generalization of the standard Fourier basis.
We can then define the convolution of f and g on a graph as
where X is a graph.
For two vectors f=(f1,⋯,fn)T and g=(g1,⋯,gn)T, the convolution of f and g can be calculated by
where Φ=(ϕ1,⋯,ϕn). Note that this formulation depends on the choice of Φ.
Practice
Let Φ be the eigenvectors of L, ordered by eigenvalue. A convolutional layer transforming node features with R∣Ω∣×fk−1→R∣Ω∣×fk, xk↦xk+1 can be defined as
where Fk,i,j is a diagonal matrix and h is a real-valued nonlinearity. Note with our previous theory the update rule corresponds to fk×fk−1 filters and fk×fk−1×∣Ω∣ parameters.
Often only the first d eigenvectors of the Laplacian are useful, which carry the smooth geometry of the graph. We can treat d as a hyperparameter and replace Φ by Φd in the equation above, which only keeps the first d columns of Φ.
This construction can suffer when the individual high frequency eigenvectors are not meaningful but a cohort of high frequency eigenvectors contain meaningful information. It is also not obvious how to do either the forwardprop or the backprop efficiently while applying the nonlinearity on the space side.
The construction above requires O(∣Ω∣) parameters. One possibility to use O(1) parameters instead is to employ
where K is a d×qk fixed qubic spline kernel and αk,i,j spline coefficients. The theory for this part seems to be ambiguous.
Last updated